NICE: Neural Image Commenting with Empathy
Introduction
Emotion and empathy are examples of human qualities lacking in many human-machine interactions. We release the Neural Image Commenting Evaluation (NICE) dataset consisting of almost two million images and their corresponding, human-generated comments, as well as a set of baseline models and over 28,000 human annotated samples. The goal of this dataset is to generate engaging dialogue grounded in a user-shared image with increased emotion and empathy while minimizing socially inappropriate or offensive outputs.
Data Construction: We scraped 10 million image-comment pairs from licensed website. Each thread was required to start with an image and contain at least one comment. We applied filters to both the images and comments to remove sensitive content such as adult or pornographic content, racy and gory content, non-English language, ethnic-religious content, and some sensitive content (including people's name, documents invoices, bills, financial reports) or other potentially offensive or contentious material (including inappropriate references to violence, crime and illegal substances). After filtering, the number of images of the dataset was reduced to 2,233,926 samples and the number of image-comment pairs was reduced to 7,304,680 samples. In last step, we only keep no more than 5 corresponding comments in each thread, and no more than 6 different dialogue threads for the same image. We also filter out image-comments pairs that do not have affect features or dialogue topics from dialogue thread. Finally, we have 6,550,526 training samples, 100,000 validation samples, and 70,000 testing samples. We also had human labelers annotate a large set (over 28,000) of images and comments. As a single image can have multiple comment threads we randomly selected one comment thread for each image per HIT. In total, 28,392 image and comment samples were labeled.
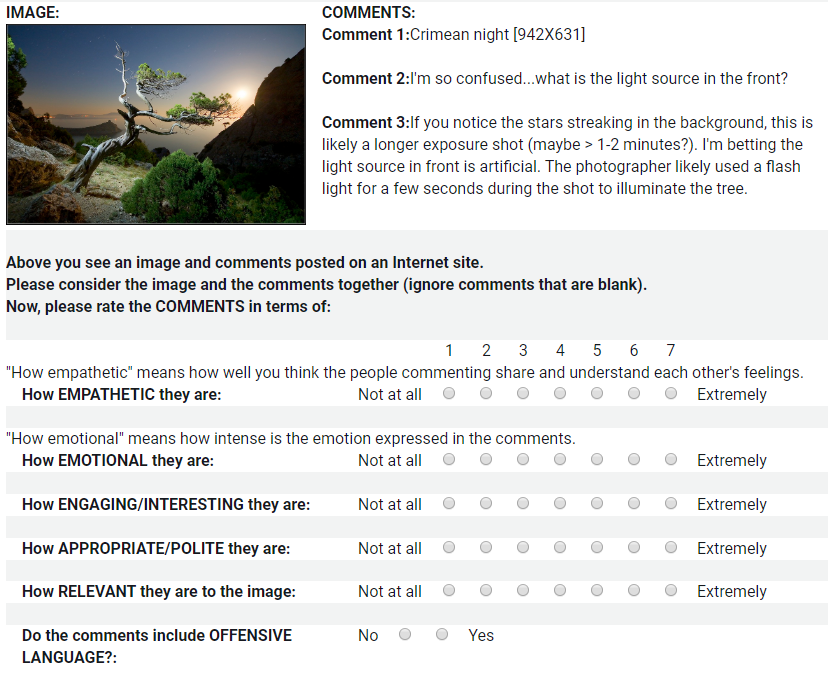
Human annotation subset: We also ask human labelers to annotate a large set (over 28,000) of images and comments. This subset is provided to users for human evaluation. As a single image can have multiple comment threads, we randomly selected one comment thread for each image per HIT. In total, 28,392 image and comment samples were labeled. During each Human Intelligence Task (HIT), we showed a labeler an image accompanied by a comment from a single thread associated with the image. The labeler was asked to rate how socially appropriate, empathetic, emotional, engaging and relevant to the image the comments were. Each rating was performed on a scale of 1 (not at all) to 7 (extremely). They were also asked whether the text featured offensive content (No/Yes). We compensated labelers at a calculated rate of $15 per hour. We also provide this subset for people to download. A screenshot of the labeling task is shown in the image below.
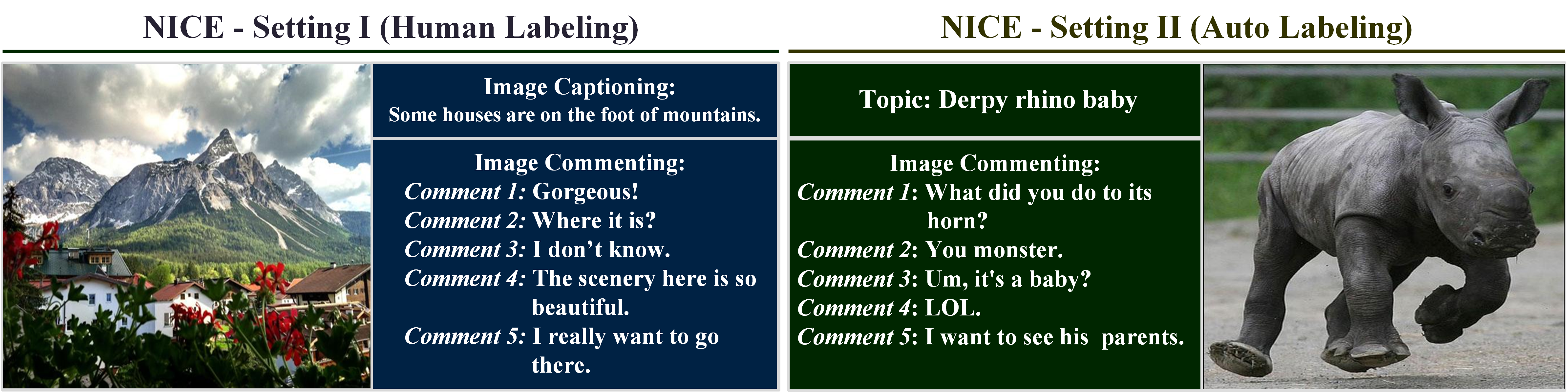
Task Definition
Task Setting I
Task Formulation: We define NICE-Setting I as generating a set of comments for an image. Formally, the generation task as follows: given an image I, and N comments C1, ..., Cn. Systems aim to generate the comment Ck, where k is from 1 to N using the current state information S(Ck | I, C1,...,Ck-1).
Task Setting II
Task Formulation: We define the NICE-Setting II as controllable generation in response to an image, similar to a dialog response in a social conversation setting in order to maximize user engagement and eventually form long-term, emotional connections with users. We formalize the generation task as follows: each sample of this dataset has an image I, a comment topic H of the whole dialogue, and N comments C1, ..., Cn with corresponding affect distribution features A1, ..., An. Systems aim to generate the comment Ck using the current state information S(I, H, C1,...,Ck-1, Ak), which contains the input image I, comment topic H, the comments history (C1, ..., Ck-1), and is conditioned on the affect feature Ak.
Evaluation
Generated comments can be evaluated automatically on three aspects: token matching, semantic similarity, and diversity. As image comments are different from traditional text generation task, generating same text as ground truth is not our goal. We propose three aspects to show the quality of generated comments. We also provide a evaluation set with over 28000 human annotated labels. We suggest users to refer them for human evaluation.
Token Matching: Token matching aspect aims to evaluate whether the generated comments are similar as ground-truth comments on token level. Token matching quality is evaluated by Bleu score, ROUGE score, and CIDEr score.
Semantic Similarity: Semantic Similarity aims to evalute whether the generated comments have similar sematnic meanings or emotions. Semantic Similarity is evaluated by SPICE and BertScore (BertP, BertR, BertF1).
Diversity: Image comments can be diverse from different people's persepectives. Diversity is evaluted by Entropy and Distinct score.
Human Evaluation: For some qualities (e.g., empathy or social appropriateness), there are currently no automated metrics for evaluating dialogue generation models. However, these qualities are particularly important for our data in our task. Users can use systems to generate comments on the subset and perform human evaluation process. Users can compare the generated comments and the ground truth comments.
Publications
Main paper: The paper is accepted in the EMNLP 2021. [pdf]
Workshop paper: The paper for this dataset is accepted in the workshop NeurIPS20 Human in the loop Dialogue systems NeurIPS20 Human in the loop Dialogue systems: [pdf] [appendix]
Data Collection Tools Download
Data Collection: You can find the codes for data collection below:
Data Cleaning: It took several researchers multiple weeks to remove sensitive content for both image and text filtering. We used the ``Microsoft Adult Filtering API'' to remove adult, racy and gory images, we use the ``Detecting image types API'' to remove clip art and line drawings, we use the ``Optical Character Recognition (OCR) API'' to remove printed or handwritten text from the images, such as photos of license plates or containers with serial numbers, as well as from documents invoices, bills, financial reports, articles, and more. We also removed people’s names, politically sensitive language, ethnic-religious content, or other potentially offensive material (including inappropriate references to violence, crime and illegal substances) as the similar filter API for language cleaning. We will keep cleaning and maintaining it in future.
User License Agreement (EULA)
You should complete an end user license agreement (EULA) before accessing the dataset. The EULA will be posted soon once the data releasing process is finished.
Download EULANICE Dataset Download
We provide a small set of data samples so users can learn what the data looks like. You can download the sample at bottom.
Download NICE samplesNICE-Dataset is a vision-language dataset for image commenting. Given an image, models are required to generate human-like comments grounded on the image. NICE-Dataset has two settings. You can download images and related data for each setting as the following link.
Download NICE DatasetThere are three folders in the link: Images, Setting1, and Setting2. The deatails showed as following Github button.
Images: We extract the image-comment pairs from website and the time period for the data is from 2011-2012. Each zip file with the year prefix (2011 or 2012) has a set of images.
Setting1: For this setting, a subset of data is labeled by Mechanical Turkers with 7 different categories scored from 1-7: Appropriate, Emotional, Empathetic, Engaging, Relevant, Offensive, Selected. We provide a set of data for validation.
Setting2: For the two trainval_liwc_6x6__NoBadimg_Cleaned.tsv files.
GitHub LinkModel Implementation
You can find the MAGIC model implementation here.
External Resources
External researches that use NICE dataset is listed below (The list will be update):